
Transcribe Audios Largos con N8N y FFmpeg sin Límites de Tamaño
Aprende a crear un subworkflow de n8n que segmente y transcriba largos archivos de audio automaticamente
¿Cuántas veces has intentado transcribir un audio largo y te has topado con el famoso límite de tamaño de archivo? Estás ahí, con tu reunión de dos horas perfectamente grabada, listo para transcribirla con Whisper o Gemini, y de pronto te da el error: “File too large”. 😅
Después de trabajar con transcripciones de audio durante los últimos días en N8N, he desarrollado un subworkflow que resuelve este problema de forma bastante elegante. Y lo mejor es que funciona increíblemente bien, tanto que ya lo he integrado en varios de mis workflows de automatización personal y laboral.
El Problema Real
La cosa es así: tanto OpenAI con Whisper como Gemini tienen límites de tamaño para los archivos de audio. Whisper te deja hasta 25MB según su documentación oficial, mientras que Gemini es un poco más restrictivo con sus 20MB (documentación aquí). Y siendo honestos, una reunión de trabajo grabada en calidad decente puede fácilmente superar esos límites.
La solución oficial que ambas documentaciones sugieren es la misma: partir el audio en segmentos más pequeños. Suena simple en teoría, pero implementarlo de forma que sea confiable y reutilizable me tomó algo de experimentación.
Mi Solución con N8N y FFmpeg
Como muchos que están experimentando con las bondades de la IA 🤖, he terminado usando N8N para automatizar varias tareas. Llevo algunas semanas probando workflows que tienen utilidad real para mi vida personal y laboral, así que aquí va mi granito de arena: un subworkflow que segmenta audios automáticamente cuando exceden el límite de tamaño.
La magia la hace FFmpeg, una CLI que nos permite manipular todo lo relacionado con lo multimedia. Lo interesante es que FFmpeg permite segmentar por duración, y con un poco de matemática podemos calcular exactamente cuántos segundos debe durar cada segmento para que ninguno supere nuestro límite de 20MB.
He probado el workflow con varios formatos (.mp3, .m4a, .ogg, .wav) y funciona muy bien con todos ellos.
Preparando el Terreno 🛠️
Antes de meternos en el workflow, necesitas tener FFmpeg disponible en tu entorno de N8N. Si estás usando N8N self-hosted como yo, esto requiere un paso adicional. Debes crear un Dockerfile personalizado con el siguiente contenido:
FROM n8nio/n8n:latest
USER root
RUN apk add --no-cache ffmpeg
USER node
ENTRYPOINT ["/usr/local/bin/n8n"]
CMD ["start"]Básicamente toma la imagen oficial de N8N e instala FFmpeg dentro de ella. Así tenemos acceso a FFmpeg desde cualquier nodo de Execute Command en nuestros workflows.
Mi docker-compose.yml se ve así:
services:
n8n:
build:
context: .
dockerfile: Dockerfile
container_name: n8n
restart: always
ports:
- 5678:5678
environment:
- N8N_HOST=n8n.abdiel.dev
- N8N_PORT=5678
- N8N_PROTOCOL=https
- N8N_PAYLOAD_SIZE_MAX=268435456
- NODE_ENV=production
- GENERIC_TIMEZONE=America/El_Salvador
volumes:
- ./n8n_data:/home/node/.n8n
- ./files:/filesHay dos detalles importantes aquí. Primero, el servicio se construye a partir de nuestro Dockerfile personalizado en lugar de usar directamente la imagen oficial. Segundo, y esto es crucial: la variable de entorno N8N_PAYLOAD_SIZE_MAX. Por defecto, N8N tiene un límite de payload de 16MB, y cuando trabajas con archivos multimedia te vas a topar rápidamente con el error “Existing execution data is too large”. En mi caso lo aumenté a 256MB (268435456 bytes).
Para determinar el tamaño del payload según tu caso, está la siguiente recomendación según la RAM disponible:
| RAM Disponible | Payload Size Recomendado |
|---|---|
| 2GB o menos | 64MB |
| 4GB | 128MB |
| 8GB | 256MB |
| 16GB o más | 512MB |
Cómo Funciona el Workflow
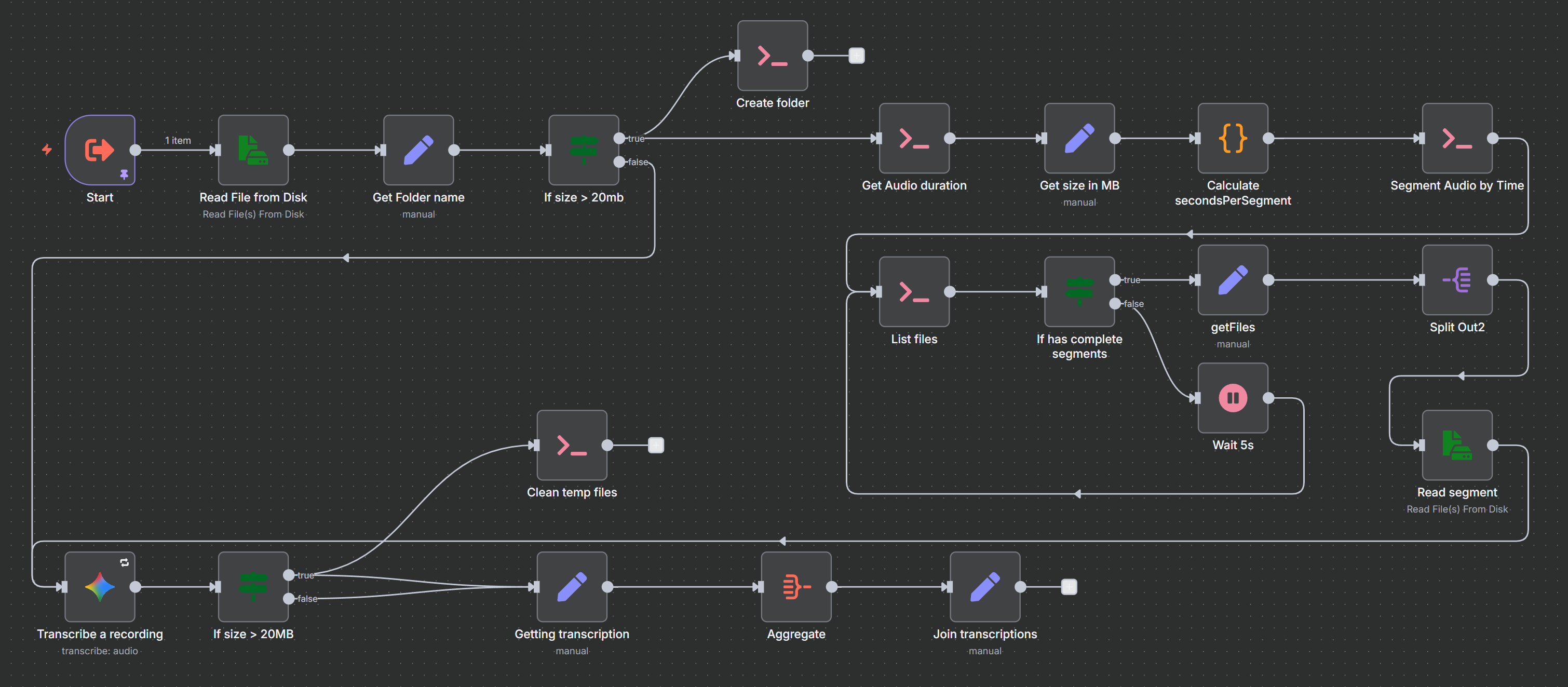
Lo diseñé como un subworkflow para que sea fácil integrarlo en otros procesos que dependan de transcripción de audio. El flujo recibe un objeto simple con el path del archivo:
[
{
"path": "/files/meetings/file.m4a"
}
]Lo primero que hace es leer el archivo del disco y evaluar su tamaño. Si es menor a 20MB, perfecto, va directo al nodo de transcripción (uso Gemini, pero puedes cambiarlo por OpenAI sin problema). Pero cuando el archivo supera ese límite, ahí es donde empieza la magia. ✨
Primero crea una carpeta temporal con el nombre del archivo. Esto es importante porque vamos a generar múltiples segmentos y necesitamos mantenerlos organizados. Luego viene un detalle curioso: FFmpeg no te deja segmentar directamente por tamaño de archivo (o al menos no encontré cómo😅), pero sí por duración. Entonces, lo que se hace es leer la duración total del audio y calcular cuántos segmentos necesito y cuántos segundos debe durar cada uno para que ninguno supere los 20MB.
Con esos valores calculados, FFmpeg hace su trabajo segmentando el audio según la duración que le especificamos. Cada segmento se guarda en nuestra carpeta temporal con un nombre secuencial. Después hay que verificar que la segmentación se haya completado antes de continuar. Implementé un loop que enlista los archivos en la carpeta temporal y, si no están todos, espera 5 segundos antes de verificar nuevamente.
Una vez confirmado que todos los segmentos están listos, el workflow los lee uno por uno del disco y los envía al nodo de transcripción. Aquí tuve que agregar una configuración importante: configuré el nodo de transcripción para que reintente hasta 3 veces si falla, porque ocasionalmente los servicios de Gemini están saturados y fallan temporalmente.
Finalmente, eliminamos la carpeta temporal con los segmentos, juntamos todas las transcripciones en un solo texto coherente y listo. Tenemos nuestra transcripción completa sin habernos preocupado por los límites de tamaño.
Obtén el Workflow Completo 📥
Si quieres ahorrarte el trabajo de armarlo desde cero, puedes importar directamente el workflow completo desde mi GitHub. Solo descarga el JSON e impórtalo en tu instancia de N8N: Workflow completo aquí.
Tips y Mejoras que He Descubierto 💡
He estado usando este workflow en producción por varias semanas y hay algunos trucos que aprendí por el camino. Si lo integras con un trigger que detecta archivos nuevos en una carpeta (como hice yo), asegúrate de habilitar la opción await write finish en el nodo de trigger. Me pasó al principio que empezaba a procesar el audio antes de que terminara de copiarse completamente, y obviamente eso no termina bien.
Hay un par de mejoras que tengo en mente pero aún no he implementado completamente. La primera es acelerar el audio antes de transcribirlo. Suena raro, pero está comprobado que funciona bastante bien y podría ahorrarte tokens si usas OpenAI. Requiere experimentar un poco para encontrar la velocidad óptima, pero es algo que definitivamente vale la pena explorar.
La segunda mejora tiene que ver con un problema inherente a segmentar por duración: es muy posible que el corte se haga justo a la mitad de una palabra. En mi experiencia, esto no afecta demasiado porque el contexto se mantiene, pero podrías agregar un nodo tipo Basic LLM Chain que revise la transcripción completa buscando incoherencias y corrija palabras cortadas según el contexto.
De hecho, este paso de limpieza con un LLM me ha resultado súper útil por otra razón: tanto Whisper como Gemini tienen un comportamiento curioso cuando no pueden escuchar bien una parte del audio. Empiezan a repetir la misma frase o palabra una y otra vez hasta que vuelven a captar algo que identifican correctamente. Un nodo de limpieza puede filtrar esos errores fácilmente.
Experimentando con Diarización 🎙️
Una cosa con la que estuve jugando fue cambiar la operación del nodo de Gemini de “Transcribe a recording” a “Analyze audio” y pedirle explícitamente la transcripción con diarización (quién dijo qué) y timestamps. Debo admitir que la diarización no era perfecta, a veces confundía a los hablantes, pero para reuniones con dos o tres personas funcionaba sorprendentemente bien. Te invito a que lo pruebes si te interesa ese nivel de detalle en tus transcripciones.
Conclusión
Este workflow me ha ahorrado un montón de trabajo manual y lo mejor es que, una vez configurado, simplemente funciona. He transcrito desde trámites personales de los que no quiero olvidar ningún detalle hasta reuniones de trabajo sin ningún problema. El hecho de haberlo diseñado como un subworkflow significa que lo puedo reutilizar en diferentes contextos sin tener que reinventar la rueda cada vez.
Si te gustan las soluciones self-hosted como a mí, échale un vistazo a mi artículo sobre gestionar variables de entorno con Infisical. ¡Es otra herramienta que corro en Docker y que me ha facilitado muchísimo el manejo de archivos .env entre proyectos!
¿Y tú, cómo manejas las transcripciones de audios largos? ¿Has probado otras técnicas o herramientas que te hayan funcionado bien? Me encantaría saber qué soluciones han encontrado otros en la comunidad. 🚀
Articulos relacionados
Cómo generar PDFs en n8n con Gotenberg
Integra Gotenberg en tus workflows de n8n para crear PDFs de manera automatizada
Mi Homelab Setup: Más de 50 Contenedores Docker en Raspberry Pi
Aprende a hostear 50+ apps en Docker, gestionar tu red y mejorar tu productividad.
No más .env perdidos: Una solución self-hosted
Mi experiencia usando Infisical para gestionar variables de entorno: instalación, configuración y uso real en proyectos JavaScript